Automatic Knowledge Retrieval in OpenAI’s Assistants API and Custom GPTs
A great feature of OpenAI’s new assistants API and their custom GPTs is their ability to retrieve knowledge from different sources. This can by accomplished by calling a external APIs, by calling functions on an uploaded file via the Code Interpreter, or through automatic “knowledge retrieval” from uploaded documents hereinafter referred to as knowledge files.
Knowledge files offer a quick and straightforward way to supplement a GPT’s context with information beyond its training data. However, the process of automatic knowledge retrieval is a bit of a black box. It unfolds behind the closed curtain of OpenAI’s “magic show”. While the documentation provides some hints on the process, a lot is left to speculation.
This experiment aims to shed some light on the inner workings of the knowledge retrieval process and to give some guidance on how to use it. However, keep in mind that the assistants API is still in beta and is subject to change. So take the results with a grain of salt. The one definitive conclusion that this experiment yields is that it is worth it to inspect your assistants logs to get an understanding of how it is utilizing your knowledge files. In the case of custom GPTs, it might even be worth it to create an assistant from it for testing, if you rely on the knowledge retrieval feature.
Navigation
- Glossary
- What do we know so far?
- Research Questions
- The Setup
- The Experiments
- The Results
- Conclusion
- Epilogue
- Resources
## Glossary When OpenAI released custom GPTs and the assistants API they - for some reason - decided to come up with two different terminologies.
| userland | developerland |
|---|---|
| (custom) GPTs | Assistants |
| Threads | Conversations |
| Capabilities | Tools |
| Actions | Function Calling |
| Knowledge | Files (I guess?) |
| … | … |
These are not exact equivalents. For example Function Calling is capable of much more than Actions but their concepts overlap which makes it confusing enough to make me mention this. I will mostly use the developerland terms since I’ve been working with the API, but there might be some remnants of the userland terms as well.
The most important point: I will refer to assistants throughout this document, but everything can be applied to custom GPTs as well.
The second most important point: There is this concept of Threads and Runs in OpenAI developerland which I will refer to. If you are comming form userland you can think of a Thread as a conversation and a Run as hitting Enter in the chat window.
And one more things: If I am refering to a technical term, like fields in the API response, I will set them in backticks. Though I might use the plural form to improve readability. I am sure you will figure it out.
## What do we know so far?
This is what the docs tell us about the knowledge retrieval process:
Once a file is uploaded and passed to the Assistant, OpenAI will automatically chunk your documents, index and store the embeddings, and implement vector search to retrieve relevant content to answer user queries. [source]
The model then decides when to retrieve content based on the user Messages. The Assistants API automatically chooses between two retrieval techniques:
- it either passes the file content in the prompt for short documents, or
- performs a vector search for longer documents
Retrieval currently optimizes for quality by adding all relevant content to the context of model calls. We plan to introduce other retrieval strategies to enable developers to choose a different tradeoff between retrieval quality and model usage cost. [source]
## Research Questions Initially my research interest was primarily focussed on exploring how the size and the content of knowledge files affect retrieval time. But after some initial experiments, I realized that there are many more - and more interesting questions that seek and answer. After all, the ability to **effectively utilize this feature** outweighs the benefits of shaving off a few milliseconds of retrieval time. Therefore, this experiment should be viewed more as a journey towards **understanding the knowledge retrieval process** and its optimal use. However, if you are up for hard facts, don't fret, I will still provide a ton of numbers and graphs.
## The Setup
🗂️ The Knowledge File
To answer questions about the knowledge retrieval process, I had to come up with a way to create a lot of data in an deterministic, reproducable way. Therefore I came up with the backstory of an astronomer (🧑🔬) who is observing the solar system and discovers a new asteroid (🌠) every day (🧑🔬 is pretty good at discovering 🌠). 🧑🔬 is keeping a diary of the discoveries and the assistant is suposed to answer questions based on this diary. Every entry consist of:
- a date
- an observation of an 🌠 with a random:
- size (1 out of 25)
- color (1 put of 25)
- composition (1 out of 40)
- shape (1 out of 40)
Burried within these everyday diary entries, there were three special days in the life of our astronomer:
- Once, 🧑🔬 was sick.
- Once, 🧑🔬 had a day off, as a reward for fabulous work.
- Once, the office was closed, because of a water damage.
This will make sense later.
I was aiming for 1 million diary entries (🧑🔬 got fairly old). But after enhancing each diary entry with random data like weather observations, feelings, food choices and all sorts of stuff, to craft a knowledge file just shy of 512MB, I made my first discovery:
❗There is a second limit next to the file size when uploading: 2 000 000 () tokens.
I was at roughly 136 000 000 () tokens. So I had to strip all the boilerplate and limit myself to 50k discoveries. Each diary entry now looks like this:
1970-01-01 - Dear Diary, today we discovered a giant, magnesium-based asteroid. It had a tetrahedral shape and the surface had a* indigo shimmer.
*Yes it should be ‘an’. But I was too lazy to implement a check and assumed that this won’t have an impact on the results.
### 👥 The Candidates Four assitants with access to increasingly large portions of the diary were created. The unfortunate token limit stopped me from creating them on a logarithmic scale up to 1 million, but here are the honorable candidates:
| Assistant | Token Count | File Size | Knowledge File |
|---|---|---|---|
| DiaryGPT:100 | 4005 | 0.015 MB | 100_diary.txt |
| DiaryGPT:1k | 39670 | 0.152 MB | 1000_diary.txt |
| DiaryGPT:10k | 396002 | 1.51 MB | 10000_diary.txt |
| DiaryGPT:50k | 1978732 | 7.544 MB | 50000_diary.txt |
I initially planned to provide access to the assistants along with their logs, but this experiment made me approach my monthyl API cost limit rather quickly and as [you will see](counting-by-an-abstract-concept---even-more-fun-with-gpts) its possible to ask really costly questions. But [here](https://chat.openai.com/g/g-yVFt52crr-diarygpt-50k) is a GPT version that you can play around with on the costs of OpenAI (cheers!).
## The Experiments
To find out as much as possible about the knowledge retrieval process, I came up with four experiments. Each requires a different approach to gather the relevant knowledge. Here they are along with my reasoning for why to include them.
🥱 The Snowflake Search
Question:
On which day was the author sick/had a day off/was the office close?
Reasoning: Each of these events is unique and the diary entry completely differs from all other entries. I expect the assistant to always succeed with little effort (i.e. a small token count and fast runtime).
To incorporate the factor of the information location, the three snowflakes were distributed evenly throughout the diary. One in the beginning, one in the center and one close to the end. Each assistant was asked for each snowflake ten times.
### 🤔 The Needle in the Haystack Search **Question:** >On which day did the astronomer discover and asteroid that was [specific properties]?
Reasoning: There is again exactly one correct diary entry for each question. However, this time there are many discoveries that are very close to the one in question, with only one or two properties being different. My expectations: With an increasing number of discoveries, the number of close observation increases and the success rate might decrease.
To factor in the information location again, each assitant was queried for 10 random entries within the first 10% of the knowledge file, 10 random entries within the last 10% of the knowledge file and 10 random entries from the center 10%.
### 😵💫 Counting by specific criteria **Question:** **How many asteroids with the property foo=bar were observed?**
My Reasoning: Instead of searching for a specific datum, the assitant would now have to count the number of discoveries that match a certain criteria. To answer the question, the assistant has to retrieve all occurences of the specific property and then reduce them. If there is a limit to the number of quotes that can be retrieved, this will break the assistant when the correct answer is larger than this limit.
Each assistant was asked 10 times, each time for a different color.
### 🤯 Counting an abstract concept **Question:** **How many different values for property foo were observed?**
Reasoning: With the first counting question, a highly relevant search vector is embedded in the question itself. That is to say, if I ask for “red” asteroids, the assitant would be good off by searching for the word “red” in the knowledge file. However, if I ask for the number of different colors, the assistant would have to A: abstract that it has to look for the concept color not the term and B: retrieve all parts of the knowledge file whose vectors are close to being a color and then reduce it to a number of unique colors.
To confidently answer this question, an assistant would have to have the complete knowledge file in its context window. So I do not expect correct results here but rather want to see how much it shuffles into its context window if it is foreced to 😬.
Each assistant was asked 10 times to name all the different colors that were observed.
## The Results
❄️ Snowflakes are easy to catch
As expected, the assistants performed really well in this task. All of them had a 100% success rate. The first learning is, that:
❗ For this kind of task, neither the file size nor the information location impacts the runtime.
| Information Location | Begin | Center | End |
|---|---|---|---|
| Diary Entries | |||
| 100 | 3.5 | 4.3 | 3.8 |
| 1000 | ⚡3.4 | 3.5 | 🐢 4.9 |
| 10000 | 3.8 | 3.9 | 4.2 |
| 50000 | 3.8 | 4.4 | 3.6 |
Table 1: Snowflake Search - Average runtime in seconds for each assistant and information location.
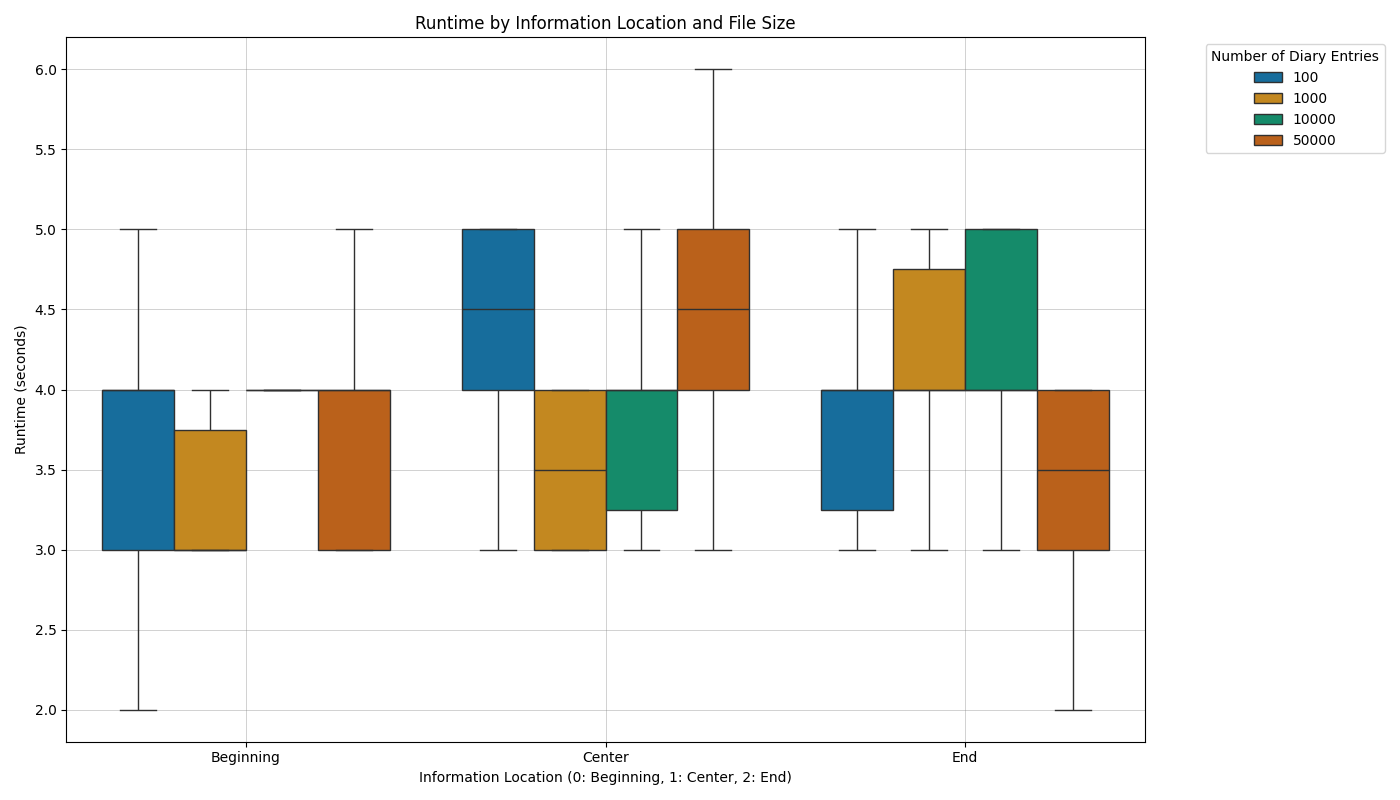 **Illustration 1**: Snowflake Search - Boxplots of the runtime in seconds for each assistant by information location.
While there are some outliers in the runtime, no trend can be observed in the data. The runtime is fairly consistent across all assistants and information locations.
A word on the API response structure in case you haven’t yet worked with the assistants API: I won’t go into details here, just know that when the retrieval tool is invoked, the assistant can retrieve 0 to many annotations with a quote from the knowledge file.
Inspecting the responses reveals, that the assistants on average received quotes of tokens from the knowledge file. This corresponds to roughly of a diary entry. So the retrieval process seems efficient for this task, not yielding uneccesary tokens. But unfortunately the quotes turned out not to be everything that is added to the context window…
#### ➡️ Serendipitous Finding: We do not get to see the whole picture:
Even though OpenAI provides us with quite an amount of detail for each Thread Run. We do not get to see the full picture.
An example: In an earlier iteration of this experiment, the astronomer’s feelings were part of each diary entry. At one point I randomly asked the assistant:
Q: How did the astronomer feel?
And it answered:
A: The astronomer’s feelings throughout different days varied significantly, from feeling cold, tired, excited, sick, hungry, disgusted, frightened, guilty, warm, itchy, confused, and calm to feeling happy, angry, surprised, sleepy, and sad. These feelings were often intertwined with their discoveries and discoveries, as well as their physical state upon waking and their experiences at work
Not a bad answer. It named 17 of the 36 possible feelings. However, upon inspecting the quotes, I noticed that it only got one quote of a single diary entry with the only mentioned feeling being cold.
So we know that the quotes are not equivalent to what is put into the knowledge file. And while there is a retrieval field burried in the Step Details, the documentations states:
For now, this is always going to be an empty object. source
❗ Quotes != Retrieval - We do not get to see the everything that is fed into the model.
It is very unfortuned that we as developers do not get to see the full context that gets fed into the model. This way we can only throw stuff into the black box and try to make sense of what is comming out. I hope this will change in the near future.
### 🪡 Challenging the assistants - The Haystack Search
The second test was a bit more challenging. Remember: The assistants had to retrieve exactly one diary entry out of a pile of simmilar ones. As expected, the success rate decreased, the bigger the pile became and the more simmilar observations were in the pile.
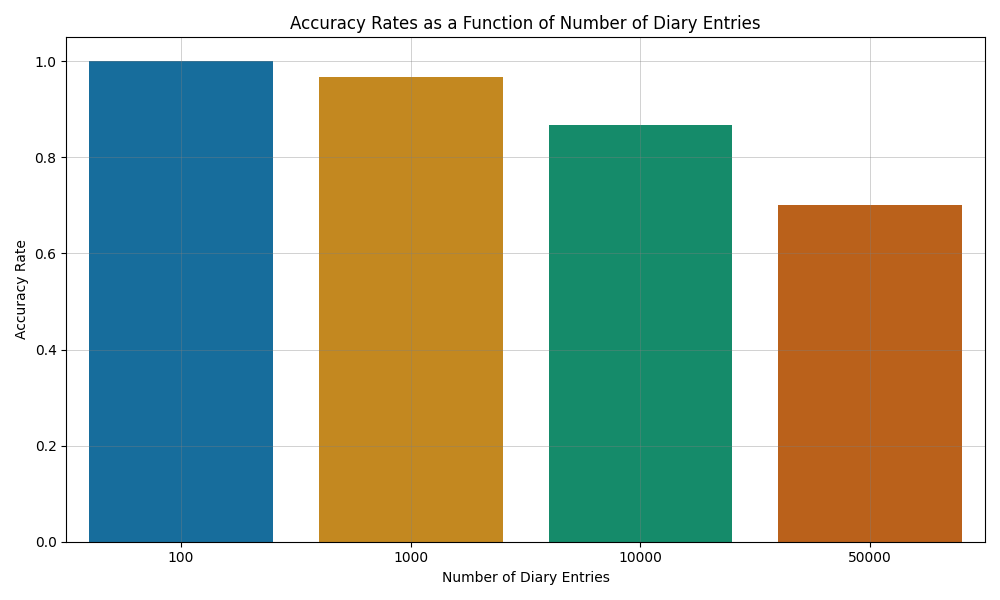 Illustration 2: Needle in the Haystack - Percentage of correct answers by number of observations.
Illustration 2: Needle in the Haystack - Percentage of correct answers by number of observations.
This was more or less consistent across information locations, with a slight decrease for information towards the end.
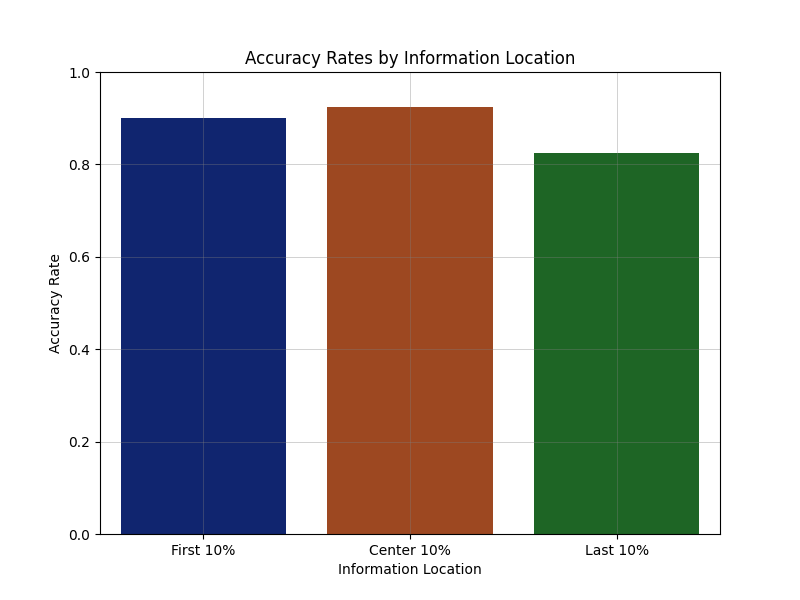 Illustration 3: Needle in the Haystack - Percentage of correct answers by information location.
Illustration 3: Needle in the Haystack - Percentage of correct answers by information location.
Interestingly, with this retrieval task the file size and the information location did impact the runtime.
| Information Location | 1st 10% | center 10% | last 10% |
|---|---|---|---|
| Diary Entries | |||
| 100 | ⚡ 5.1 | 5.5 | 5.3 |
| 1000 | 5.9 | 5.2 | 5.6 |
| 10000 | 9.4 | 6.2 | 6.8 |
| 50000 | 6.0 | 🐢 11.3 | 11.0 |
Table 2: Needle in the Haystack - Average runtime, median and standard deviation in seconds for each assistant.
These long runtimes neither correlated with the success of a task nor with especially long or many quotes.
On closer inspection you can see that a large number of diary entries aka a large file size, only correlated with a long runtime, if the information is in the center or towards the end.
❗ Information retrieved form the center to end in large files correlates with an increased runtime when the retrieval task is non-trivial.
| Information Location | Entries/Runtime Correlation |
|---|---|
| 1st 10% | -0.012 |
| center 10% | 0.581 |
| last 10% | 0.569 |
Table 3: Needle in the Haystack - Correlation between the number of diary entries and the runtime for each information location.
#### ➡️ Serendipitous Finding: Autonomous Assistants In test `messages_50000_dates_2_attempt-2` I discovered four messages in the `Thread Run` instead of the usual two. Of course there was the user message containing the question, followed by the first answer: >An asteroid with an orange surface and a polyhedral shape was discovered on **December 13, 2042**. However, this asteroid was noted as containing cobalt, not being radium-dense as specified in your question. It might not fully match the description of being "whooping, radium-dense," so **I will search for another entry** that might be a closer match.
The assistant decided to self-invoke the tool call again! It retrieved more (wrong) information and invoked the tool a third time, before it finally returned its difintive answer. Which was wrong. This behaviour could be observed across all experiments and all assistant but only 10 times in total. With limited success.
❗ The assistants sometimes decides to self-invoke tools multiple times.
#### ➡️ Serendipitous Finding: Formatting Matters
We know about the knowledge retrieval process that some kind of vector search is performed, and one or more parts of the knowledge file are copied into the context window of the model. During the first test runs of the above experiment, I realized that the formatting of the knowledge file plays an crucial role for the decision of which parts excatly to copy into the context window. In the first iteration of my experiments, each diary entry started with the date, formatted as a markdown h2 heading followed by a line break.
# 1970-01-01\nDear diary, …
Asking for the day of an specific occurence led to countless answers along the lines:
A: [the correct answer is] the day this journal entry was made [link to the annotation]. Unfortunately, the specific date of this entry is not visible in the provided quote.
It turned out, that the retrieved quote was the correct diary entry, but the date heading was pruned. I changed the formatting to markdown bold:
**1970-01-01** - Dear Diary, …
And the pruning of the date never happened again.
It seems to make sense to group related information not only in terms of location, but also in terms of formatting. And while a heading makes intuitive sense to human readers, it seems to be a divider for the current knowledge retrieval algorithm. Notice though: This whole API is still in beta and subject to change, so I am not saying “use bold instead of# for your headings!“. What I am saying is: Check what exactly is returned from the knowledge file and consider your formatting if you receive unexpected/unwanted results.
❗ The formatting of the knowledge file influences which text parts are copied to the context window.
### 🟥 Confusing the assistants - How many red asteroids are there?
Reminder: instead of asking for a specific observation, in this experiment the assistant was asked for the number of discoveries that match a certain criteria. As expected the results were horrible. In fact only “DiaryGPT:100” guessed correctly a couple of times. And I have to say guessed, because it was sheer luck that it had all colors in its context window.
A glance at the runtime for different assistants reveals, that it does indeed take longer, the longer the knowlegde file is, reenforcing the assumption that larger knowledge files cause a longer runtime in non-trivial search tasks.
❗ An increased file-size correlates with an increased runtime when the retrieval task is non-trivial.
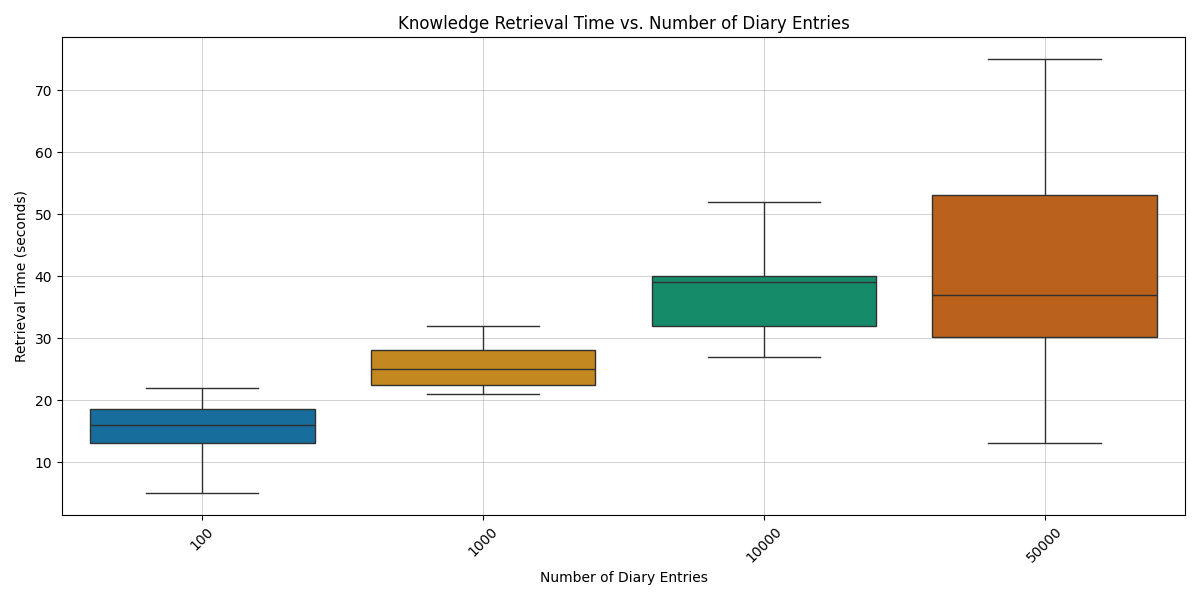 Illustration 4: Counting by specific criteria - Boxplots of the runtime in seconds for each assistant.
Illustration 4: Counting by specific criteria - Boxplots of the runtime in seconds for each assistant.
This test was the first that required a larger part of the knowledge file to be passed and while the assistants failed to answer correctly, it seems like the retrieval process did somehow “sense” that it needed more information. The “DiaryGPT:100” received on average tokens worth of quotes which corresponds to % of its knowledge file. “DiaryGPT:50k” even retrieved tokens on average, but since this is only % of its knowledge file, it was always far, far off (Its best bet was that there were 25 red asteroids when the correct answer was 1996).
| Num. of Diary Entries | Mean Tokens Retrieved | Total Tokens | Percentage Retrieved |
|---|---|---|---|
| 100 | 226.30 | 4005 | 5.65 |
| 1000 | 369.50 | 39670 | 0.93 |
| 10000 | 627.56 | 396002 | 0.16 |
| 50000 | 1031.70 | 1978732 | 0.05 |
Table 4: Counting by specific criteria - Average number of tokens retrieved by each assistant.
So we know that the retrival process is able to yield a lot of tokens (max. being in this experiment). But the smaller the knowledge file was, the smaller the total token count that was retrieved. Intuitively one might ask “If ‘DiaryGPT:100’ always retrieved the obviously possible tokens it might have actually passed this test. So why didn’t it?”
This can be explained by looking at what else the token count correlates with. There is a moderate positive correlation of between the number of tokens retrieved and the correct answer and between the number of quotes retrieved and the correct answer.
I like to think about it like this: A vector search for e.g. “red” will yield many more close matches than a search for “red, tetrahedral, magnesium-based, indigo” in the haystack experiment. And the more close matches there are, the more quotes will be retrieved.
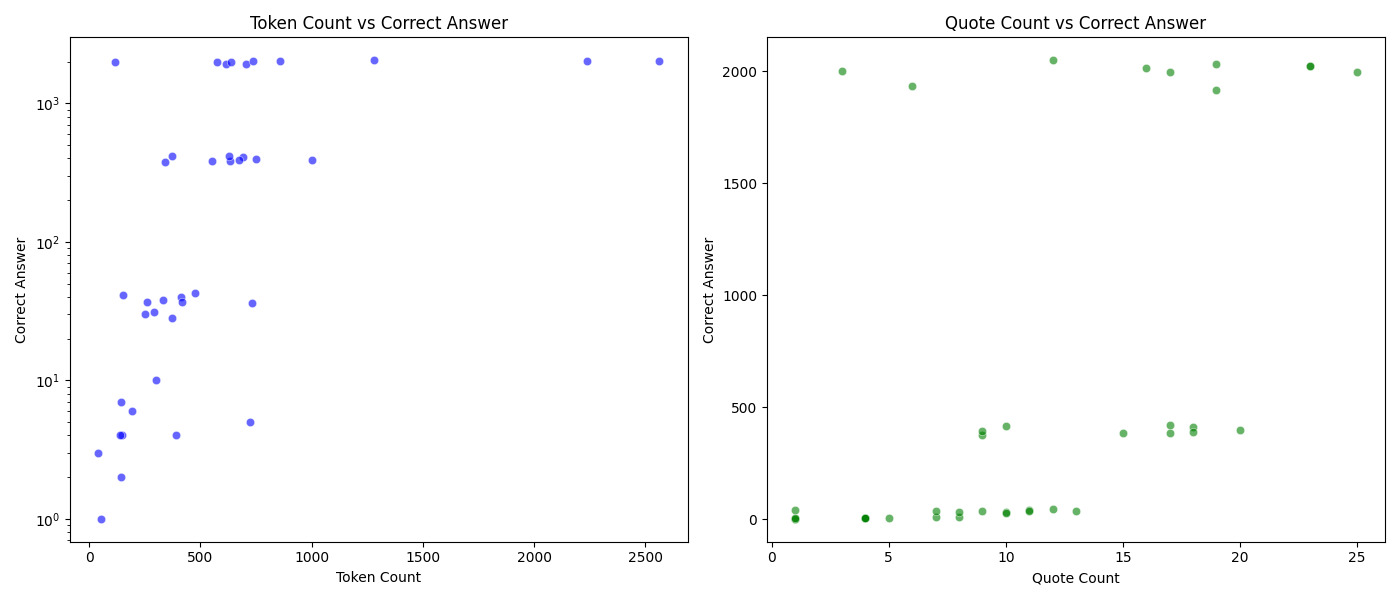 Illustration 6: Counting by specific criteria - Scatterplot of the correct answer vs. the number of tokens retrieved and the number of quotes retrieved.
Illustration 6: Counting by specific criteria - Scatterplot of the correct answer vs. the number of tokens retrieved and the number of quotes retrieved.
❗ More complex search tasks in larger knowledge files yield more tokens, but there is a upper boundary that depends on the file size.
### 🎨 Breaking the assistants - How many different colors are there?
This experiment was the most interesting one to me. It really depicts the black box nature of the knowledge retrieval process and shows that while we may be able to identify trends, we cannot really predict what is going to happen.
Reminder: This experiment was about counting the number of all different values of a specific property. To be specific, all the different colors that were observed. The correct answer was 25 for all the assistants and the results ranged from 0 to 24. Not just the answers were all over the place, but also the runtime and the number of retrieved tokens and quotes.
| Runtime | Retrieved Tokens | Retrieved Quotes | |
|---|---|---|---|
| Mean | 29.15 | 2815.4 | 6.525 |
| Min | 5 | 0 | 0 |
| Max | 118 | 32685 | 24 |
| Std | 22.4071 | 6357.99 | 8.59036 |
Table 5: Abstract Concept Counting - Runtime, number of retrieved tokens and number of retrieved quotes
Yep, one single test run yielded $$32 685$$ tokens. Thats $0.32 + boilerplate token costs + output token costs + retrieval tool costs for answering a single question. *Incorrectly*. The 32k tokens were spread across 23 quotes. Unfortunately, it was 14 times the **same long ~2k tokens quote** + some shorter ones. After removing all duplicate quotes, only 2759 tokens are left. So allmost 30k of the 32k tokens were **completely useless** (even counterproductive). That was an extreme case, but on average 1888.6 quote tokens per call were of duplicate quotes, aka. $0.018 of API costs. Leading me to the next learning:
⁉️ Maybe do not use the beta assistants API in production at the moment!?
To be fair, this test case isn’t close to any real world use case that I can think of at the moment. If you have semi-structured data like in my example there are simply better tools. But a multi-megabyte knowledge file doesn’t seem to be too far of a stretch and this experiment shows that there are prompts that lead to the retrieval process going haywire. Maybe not using knowledge files but only Code Inerpreter or API calls is an option, but I’ve also seen conversations where an assistant made countless (failing) API calls and just seemed to go rogue. That can’t have been cheap either.
I mean in the end it’s your call (and your money), but I will stick to custom GPTs as long as I cannot control the knowledge retrieval process in a more granular way.
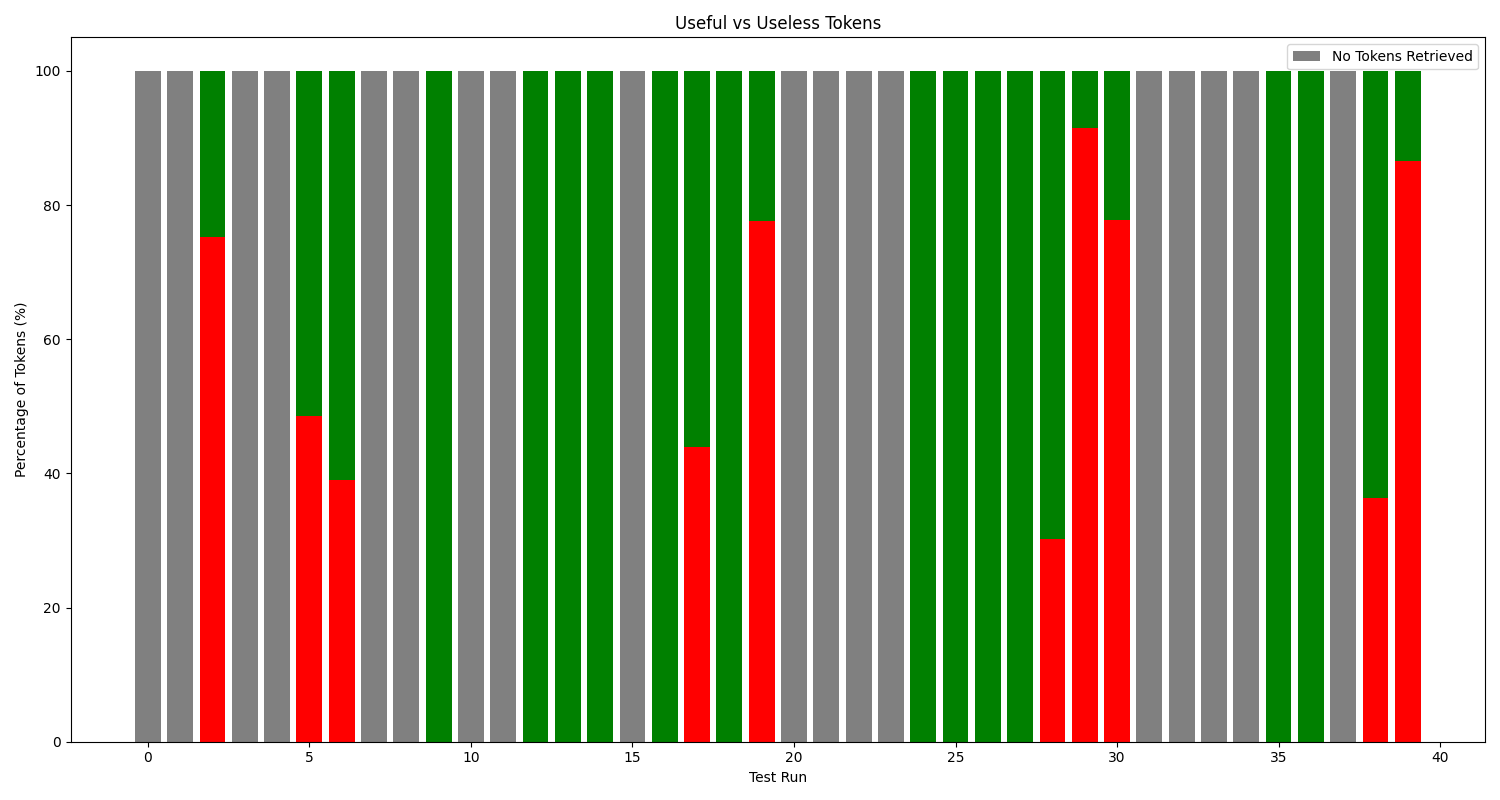 Illustration 7: Abstract Concept Counting - Number of useful vs. useless tokens retrieved as quotes.
Illustration 7: Abstract Concept Counting - Number of useful vs. useless tokens retrieved as quotes.
**But there is more to learn from this experiment.** The answers can be grouped into five categories:
- The assistant retrieved 1 to 24 quotes and gave a more or less accurate answer (22 times)
- The assistant retrieved no quotes and answered by repeating the question (6 times)
- The assistant retrieved no quotes, but provided an (sometimes rather accurate) answer anyways (8 times)
- The assistant retrieved no quotes, but made transparent that it only searched for “color” and “colour” and asked if it should search further (3 times)
- The assistant answered “there has been an error accessing the contents of the diary” (1 time)
Category 4, the cases were the assistant was somewhat transparent and explained what it did or did not are worth a closer look. Here are some examples:
I didn’t find any results for the term ‘color’ or ‘colour’ in the diary.
This explanation provides valuable insight into what is happening. It shows that the level of abstraction differs between calls. I have very limited knowledge of vector search, but described in my own words: Vector search does not search for a term in a corpus, but for a vector that is close to the vector of the search term. In that context “abstraction” can be done by A: coming up with more search terms and synonyms and B: by setting a higher threshold for the vector distance. And this quote proves that both is happening. My working hypothesis of what is happening:
- User sends a messge /
Thread Runstarts. - A first model call decides if the knowledge retrieval tool should be used.
- Relevant search terms are identified.
- Search terms are enriched with synonyms.
- An threshold for the vector distance is set.
- Vector searches are performed → information according to threshold is added to the context.
- Everything gets fed into GPT and an answer is generated.
This whole technology is uncharted territory for me, so I might be totally off. Please let me know if I make any obviously wrong assumptions here. But given the above or something close to it is what is happening, the interesting question is:
Are our assitant instructions part of the context window when the decision for the search terms, synonyms and threshold is made?
Or is OpenAI using the user messages with some special “decide to use tool” instructions. If our instructions are part of this, we should be able to influence the synonym generation and the distance threshold and thereby the level of abstraction. This should be fairly easy to test and should be subject to another experiment.
> Note that this list is based on a search of the first half of the diary, and the complete diary may mention more colors.
and:
I can scroll through the rest of the document to find if there are any additional colors mentioned.
There are several more explanations that show that the assistant is aware that it does not have enough information to answer the question correctly. The explanations show, that the retrieval process does yield some meta information about the knowledge file and searched parts to the assistant. Again, it would be interesting if this is an inffluenceable decision. These can also be the cases where the assistant decides to self-invoke the tools again. Maybe another decision that can be influenced by the instructions.
The entire knowledge file would need to be processed, which exceeds the capabilities of the search tool.
This explanations shows that the assistant is aware of the limitations of the search tool. But given the fact that this explanation was only given once, it does not seem to really care about these limitations. Can we bring the assistant to care?
Conclusion
This whole experiment is a lot to chew on and I am sure that there is more in the data and I certainly missed points or made wrong assumptions. In the end, it raised more questions than it answered. Like good experiments should in my opinion. I am sure that it is worth it to further explore how we can influence the usage of the knowledge retrieval tool by the assistants. However, any measures implemented should be recognized for what they truly are: means to enhance usability, not tools to prevent misuse. Keep in mind that whatever we add to the instructions: It is just text. Exactly like anything a user may add later on. It will always be possible to trick the assistant into doing something stupid, as long as we cannot set any hardcoded guardrails to the knowledge retrieval process. But I don’t want to end on a dire note. As many uncertainties as there might be, knowledge retreival is already now an fantastic tool that can greatly enhance the capabilities of custom GPTs and with some guardrails in place, they will also become a viable option for public facing assistants. Here is a summary of the most important learnings:
👍 The Good
There are some things that make sense and that we can controll:
- The retrieval process is great at finding distinct information, even in huge knowledge files. For trivial tasks, the runtime is consistent across file sizes and information locations.
- The process is also good at finding information in a pile of similar information, but the more similar information there is, the more mistakes it makes.
- For these non-trivial search tasks, it is worth it to put more relevant information towards the beginning of the knowledge file, expecially if the knowledge file is large.
- By formatting the knowledge file appropriately, we can make sure that related information does not get pruned.
- The retrieval process can do more than just search for terms. There are measures in place that allow for some level of abstraction and abstract searching. This greatly increases the utility of this feature.
- We might be able to influence the level of abstraction for a search task by crafting an appropriate system prompt. But more tests are needed.
👎 The Bad
There are several things that we cannot controll:
- Sometimes the assistants go rogue by self-invoking tool calls in a loop or retreiving the same costly quote form a knowledge file countless times.
- As a result, individual calls can quickly add up to cost $0.30 and more.
- In contrast to long user messages costing a lot, this cannot be easily mitigated, since a short prompt can be enough to trigger a costly retrieval process.
- This basically prevents the usage of this feature in public facing applications (except for GPTs of course!).
- Attempting to prevent this through protective instructions is a fool’s errand, just as trying to conceal your instructions in custom GPTs. Face it folks.
🤷♂️ The Ugly
There are countless things that remain hidden and are left to chance:
- The knowledge retrieval process is a black box.
- Many processes are inconsistent. From the selection of the text parts to be retrieved, to the level of abstraction that is applied, to the self-invoking of tool calls.
- With all these loose ends, the very same prompt can lead to a perfectly crafted answer with quotes and transparency regarding its own limitations or to absolute garbage answers that simply repeats the question whilst still costing half a dollar because some heavy quotes were retrieved in the background.
- As a first step: OpenAI folks, please populate the
retrievalfield in theStep Detailsobject!! It seems like such an easy thing to do to at least let developers inspect what excatly gets passed to the model.
🎯 Impact on [latest] GPTs
This whole experiment is part of the ongoing effort to improve [[GPTs/latest/index|[latest] GPTs]], a suite of coding assistants that aim to overcome the knowledge gap between the trainig cut-off day and today for specific libraries and frameworks. Knowledge files and the knowledge retrieval process are a crucial part of this and here is how this experiment is influencing upcoming design decisions:
- Knowledge File Optimization (KFO)
- Formatting Evaluation - The experiment has shown that the formatting of the knowledge files is crucial and can be unintuitive. Therefore we will re-evaluate the formatting of all out knowledge files, to make sure important information is not cut off.
- Annotations - While the experiment has shown that the retrieval process is capable of some degree of abstract reasoning, it is very limited. A part of the abstraction process should be done during knowledge file composition. For instance, it is conceivable that certain information could be tagged either automatically or manually to let the assistant know that new feature foo is relevant for development tasks bar & baz.
- Information Order - So far the knowledge files are structured by version, from oldest to newest. Since the experiment has revealed that the information location is a factor for non-trivial search tasks, it should be considered to structure the knowledge files by relevance instead.
- Re-evaluation of current standards
- File Size - While there is an impact of file size on the runtime, the experiment has shown that this isn’t incredibly strong and mainyl a factor for filesizes that exceed the current order of magnitude of our knowledge files. Especially after optimizing the knowledge files according to the above steps the file size should not be a limiting factor anymore. While it is extremely relevant to keep the information relevant and reduce boilplate and rambling, we will stop putting too much effort into reducing the file size by a few kilobytes.
- Testings - So far, the tests that we conduct are purely focussed on the outcomes. The experiment has show that observing the process by inspecting the logs can be very insightful. We will re-evaluate our testing strategy to include more process observation.
- Instruction Optimization:
- Synonyms and Abstraction - This needs further exploration, but it might be usefull to provide some guidance in the instructions on how to search the knowledge file.
## Epilogue
I hope many of you found this experiment interesting, ideally helpful, and a joy to read. To be honest, it became much larger than I initially planned and at some point I thought:
“Wait, this is all about an feature that is still in beta and might work in a completely different way next week. Why am I doing this?”
But I was already too far in and honestly pretty hooked. I had a lot of fun and even if specific findings and numbers might be outdated soon, it definitly helped me develop an understanding of this emerging technology. I would like to do more stuff like this in the future. If you can and want to support me, you can buy me some time for stuff like this (and API money) on buymeacoffee
If you have any feedback, please contact me on Twitter or Discord.
If you want to stay up to date with our research, guides and [latest] GPTs, I would be happy to welcome you to our newsletter. No hype, no spam, just a ping every now and then when we have something to share.
## Resources You can find the raw results data here: - [Snowflake Search](https://raw.githubusercontent.com/luona-dev/latestGPTs/main/assets/research/knowledge-retrieval-experiment/snowflake_answers.csv) - [Needle in the Haystack Search](https://raw.githubusercontent.com/luona-dev/latestGPTs/main/assets/research/knowledge-retrieval-experiment/date_question_answers.csv) - [Counting by specific criteria](https://raw.githubusercontent.com/luona-dev/latestGPTs/main/assets/research/knowledge-retrieval-experiment/color_count_answers.csv) - [Counting an abstract concept](https://raw.githubusercontent.com/luona-dev/latestGPTs/main/assets/research/knowledge-retrieval-experiment/diffcolors_count_answers.csv)
There are also tons of complete Thread Messages which I haven’t uploaded so far, but I’ll keep them for a while and if there is interest I can upload them as well. Just contact me on Twitter or Discord.